- .......
- Design Phases
The design of Data Processes focuses on the functional aspects and includes the design of procedures for: data ingestion, transformation, production, publication, etc. This activity is the classical Extract Transform Load, ETL, and/or Extract Load Transform, ELT of data warehouses and data lakes.
So that the Processing Logic activities can be those of:
- Data Ingestion, gathering, harvesting, grabbing, web page crawling, etc.
- Data Transformation, transcoding, decoding, converting, reformatting,..
- Data load/save to storage, retrieve from storage
- the load/save activity is typically performed loading (sending) data to an Internal Orion Broker V2, or on some MyKPI storage. In both cases, the data arrives into the OpenSearch.
- the retrieval is typically performed using one of the several query / search nodes provided from the Snap4City Library on Node-RED.
- Many other kind of storage connections are accessible in Snap4City Processing Logic (IoT App). For example, with Azure, MySQL, ORACLE, AS400, etc.
- Data production, generation, etc.
- Data publication, post in other channels of any kind, etc.
- Server-Side Business Logic as described in the following.
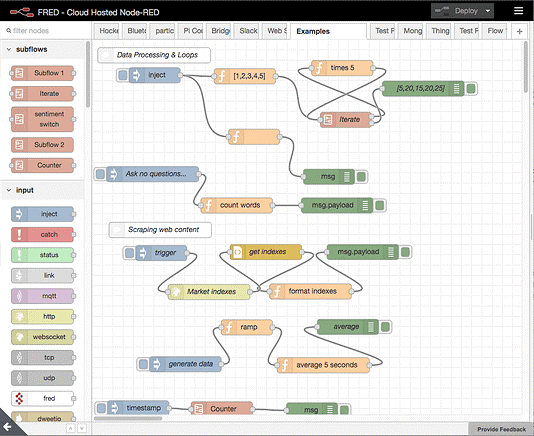 Figure: a Node-RED with multiple Folders/Labels, and
Figure: a Node-RED with multiple Folders/Labels, and
in the current folder Examples you have 5 independent flows.
In Snap4City, the activity of Processing Logic is strongly simplified since all these functional aspects are easily developed via Node-RED flows exploiting a large set of nodes from Snap4City libraries. This approach is based on visual programming where the usage of JavaScript is quite limited. In Node-red, there are several libraries to perform all kinds of functions in the above categories and much more. Snap4City implemented 4 Node-Red libraries dedicated to Smart City IoT platform: https://flows.nodered.org/search?term=snap4city
Processing Logic is implemented in Node-RED in which you may have different folders, and in each folder, you may have multiple flows, processes. You can also group nodes, link them, create macros, etc. (see the figure above here).
For each Data Process in Processing Logic (IoT App) / Node-RED one should answer at questions and identify:
- What process must be implemented to process the data/entities?
- Which kind of data formats, protocols and channels will have to be used?
- Which data/entity models would be exploited and produced?
- What are the data transformations required (e.g., transcoding)?
- How many independent data flow are needed?
- For each of them: In/out formats and Data Model if any?
- Complexity and possible nature: ingestion, production, transform, load, etc.?
- Which kind of Node-Red block/nodes can be used, are they available?
- How much data will arrive per day, per month, per year; and thus, which is the volume in terms of byte that I am going to collect?
How to proceed:
- A Processing Logic should be composed by a set of independent Flows for the scalability and for the simplicity, for example:
- Receiving data from the field (if you connect data reception with processing means that you module for processing/assessing will lock the reception of other messages)
- Assessing the data according to the status and producing results
- Providing notifications
- Preparing reports
- Sending reports
- Computing monthly update
- Receiving events from dashboards, Sending reaction to dashboards
- Etc.
- Decompose your problem and sequence diagram in a set of independent flows as much as possible. An independent flow is one that starts from a certain event (periodic or provoked from the arrival of a message into a broker (ORION or MQTT), get some data, do some transformation, and finishes with one or more actions such as:
- start of a flow can be based on event, you can realize Event Driven flows. In Snap4City Events can come from:
- Brokers: MQTT, Orion Brokers, or others…as well as from any listener-based protocol
- MyKPI changes via Snap4City nodes
- Dashboard events via Snap4City nodes
- Manual start via an Inject Node
- Programmed periodic start from an Inject Node
- Eventual HTTP call API, but its strongly discourages as state in other paragraphs.
- Etc.
- actions/activities such as to
- get some data from storage via search node of Snap4City Library
- perform a data transformation, etc.
- activate the Data Analytic process, etc.
- send a new Entity Message in the ingestion Broker (e.g., NGSI V2 Orion broker) and thus into the storage to change the Entity Instance status,
- send an event to some broker or MyKPI (this can provoke action on Dashboards elements and on Synoptics),
- provide a message into a widget dashboard for directly providing some changes into the user interface,
- send an email, or a telegram,
- etc.
- start of a flow can be based on event, you can realize Event Driven flows. In Snap4City Events can come from:
- Design the single independent flows with a mixt of the possible activities.
- The design can be performed using data flow diagrams, which are stream programming based.
- It may have sequences, switch, serialization (split), packing (join), distribution, communication, transformation, search, etc.
- The classic FOR programming construct to select single data structures over a vector of results is typically substituted with Split/Join, and thus processing them on single JSON message/structure. If you need you can have FOR into the Function Node in JavaScript.
- When the design of independent flows mechanism is clear the designers can pass to directly sketch the flow in Node-RED which is a visual programming.
- Incrementally improve the Processing Logic (IoT App) Node-RED flows by adding nodes needed.
- Eventual communications among different Processing Logics (IoT Apps) can be implemented as:
- Asynchronous nonevent driven by using storage.
- Even driven by using MyKPI or Orion Broker