The design and development of Data Analytics, DA, is mainly performed taking in mind that the development can be performed in Python or Rstudio. And they are automatically converted in containers exposing some API/microservices which can be called from Processing Logic (IoT App) node-RED in multiple instances or as singleton. The design of DA implies to decide their aims, for example, for implementing specific algorithms, or making predictions, anomaly detection, suggestions, statical analysis, clustering, classification, detection, recognition, etc. Most of these aims can use techniques from ML, AI, XAI, NLP, operating research, statistics, etc., and exploit a set of libraries from Python or RStudio to produce a DA Model, DAM. For example, from a training phase. Python and RStudio platforms may exploit any kind of libraries such as Keras, Pandas, and hardware accelerator as NVIDIA to use Tensor Flow, etc. The developers can access the KB and Big Data store respecting the privacy and the data licensing by using authenticated Smart City APIs. The access has to permit the reading of historical and real-time data, and saving the resulting data provided by the algorithms, for example, heatmap-related predictions, the assessment of data quality, and labels of detected anomalies.

Figure: Schema of Data Analytics development
In Snap4City, this activity is strongly simplified since the Data Analytic can be implemented in Rstudio or Python exploiting processes that are executed on:
- Dockers Containers accessing and controlling them via some API, and these can be automatically produced and manage by the platform. The management is typically performed by some Proc.Logic (IoT App).
- Dedicated servers (for example for developers, or for exploiting high performance boards as the NVIDIA, in the lack of VGPU on your cloud resources) and leaving them to access to the storage for using the data and providing results via Snap4City API, in authenticated and authorized manner.
For each Data Analytics one should identify:
- What process must be implemented by the Data Analytics?
- Which data models would be produced?
- Which data are needed?
- For each of them: In/out formats and Data Model if any?
- The process to be implemented is for training or for production?
- How many processes for production I am going to have at the same time?
- Which the execution time?
- Which is the expected precision, and which is the state of the art?
- Do I need to execute the Data analytic exploiting special hardware as NVIDIA since I am going to use CUDA, tensor flow, …?
How to proceed to design the single Data Analytic according to its nature.
- Problem analysis, business requirements.
- Data Discovery, Data ingestion, acquisition (as above presented that can give for granted).
- Data set preparation, transformation, identification of features, normalization, scaling, imputation, feature engineering, etc.
- Target Assessment Model Definition
- Identification of metrics for the assessment, KPI.
- Typically: R2, MAE, MAPE, RMSE, MSE, MASE, MAP, …
- Screening on Models/Techniques, for each Model/Technique or for the selection Model/Technique perform the
- Model/Technique Development/testing
- Best Model selection among those tested
- If needed reiterate for different parameters, features, etc.
- Comparison with state-of-the-art results.
- Needs of Explainable AI solutions: global and local.
- Deploy best Model in production, monitoring in production.
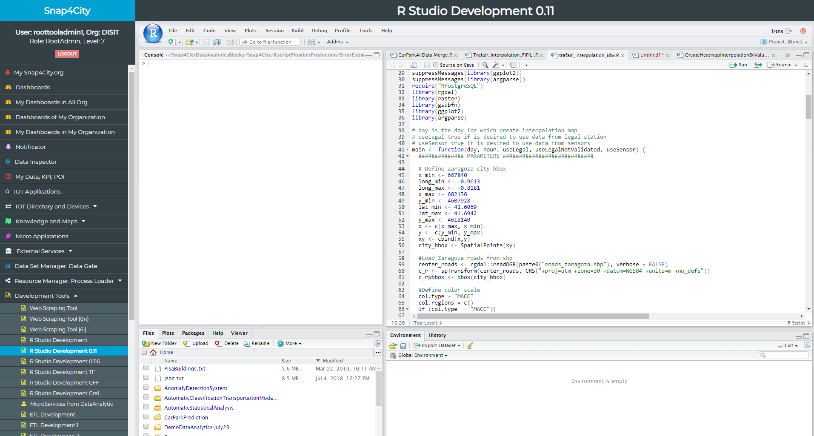
Figure: Data Analytics development in R-Studio, similar to Python which is in Jupiter HUB
In Python and/or RStudio cases, the script code has to include a library for creating a REST Call, namely: Plumber for RStudio and Flask for Python. In this manner, each process presents a specific API, which is accessible from an IoT Application as a MicroService, that is, a node of the above-mentioned Node-RED visual programming tool for data flow. Data scientists can develop and debug/test the data analytic processes on the Snap4City cloud environment since it is the best way to access at the Smart City API with the needed permissions. The source code can be shared among developers with the tool “Resource Manager”, which also allows the developers to perform queries and retrieve source code made available by other developers.
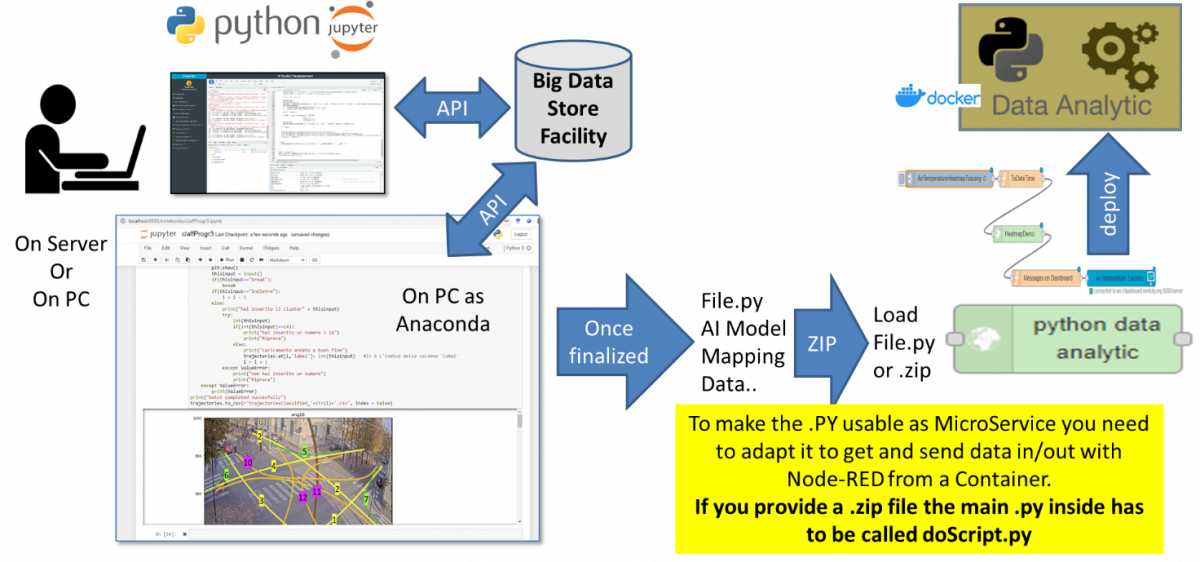
Figure: Data Analytics development flow in Python.
This description of the flow refers to case in which the Python or Rstudio are created to be used as MicroServices as contained from the Proc.Logic / IoT App. An alternative is to develop the Data Analytic to be used as standalone services, working on API, or providing some REST Call, and thus usable from Proc.Logic / IoT App according to the API or by collecting results on database. These aspects are described into the training course.
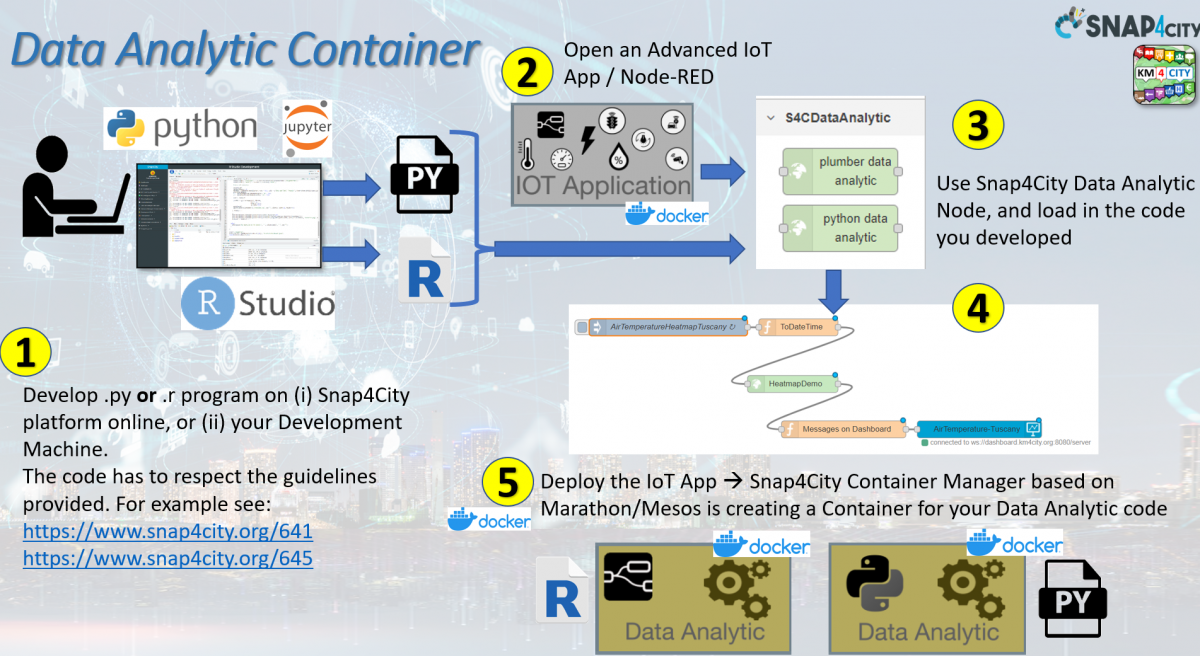
Figure: Data Analytics development flow in Python and integration into Proc.Logic / IoT App.
In Snap4City, there is a specific tutorial for the Data Analytic development with several examples: https://www.snap4city.org/download/video/course/da/.
Read the mentioned slide course and/or platform overview to get a list of Data Analytics in place: https://www.snap4city.org/download/video/Snap4City-PlatformOverview.pdf.
We also suggest reading the Snap4City booklet on Data Analytic solutions.
https://www.snap4city.org/download/video/DPL_SNAP4SOLU.pdf.